Generative AI Can’t Replace Expertise: It Exposes Its Absence
Introduction: The Illusion of Instant Data Science
Generative AI tools have arrived in data science with remarkable speed. In just a few years, tasks that once required hours of careful work,writing code, generating plots, summarizing results can now be completed in seconds with a well-phrased prompt. For students and practitioners alike, this has created a powerful and seductive belief: maybe I can skip the hard parts now. Why struggle through debugging, statistical assumptions, or exploratory analysis when an AI tool can seemingly do it for me?
This belief is understandable. The outputs often look polished, confident, and technically correct. Code runs. Charts render. Explanations sound fluent. To many users, this feels like progress, perhaps even a sign that deep expertise is becoming less important.
Yet something curious happens in practice. Two people can use the same generative AI tool on the same data science problem and walk away with dramatically different outcomes. Experts often extract real value: speed, clarity, and better alternatives to consider. Beginners, on the other hand, are more likely to produce fragile analyses, misleading conclusions, or outright errors,sometimes without realizing it (Bommasani et al. 2021).
This raises an uncomfortable but important question: if generative AI is so powerful, why does it seem to reward expertise rather than replace it?
What Generative AI Really Does (and What It Absolutely Doesn’t)
To answer that question, it helps to be precise about what generative AI actually does. At its core, generative AI systems,such as large language models,operate by identifying patterns in massive collections of text and code and then generating outputs that statistically resemble what they have seen before. They are exceptionally good at producing plausible responses.
What they do not do is reason about truth in the way humans do. They do not understand the data-generating process, the domain context, or the real-world consequences of an analysis. They do not verify assumptions. They do not know when something is conceptually inappropriate, only when it looks syntactically reasonable.
This is why generative AI outputs so often feel authoritative. The language is fluent. The structure is clean. The code follows conventions. But fluency is not the same as correctness (Ji et al. 2023). In data science, syntactic correctness: code that runs, formulas that are well-formed, is only the starting point. Conceptual correctness is what matters: Is this the right analysis for this problem? Are the assumptions justified? Are the conclusions supported by evidence?
Generative AI excels at mimicking competence, but it cannot verify truth. That responsibility remains squarely with the human using it.
The Data Science Workflow: Where Expertise Gets Exposed
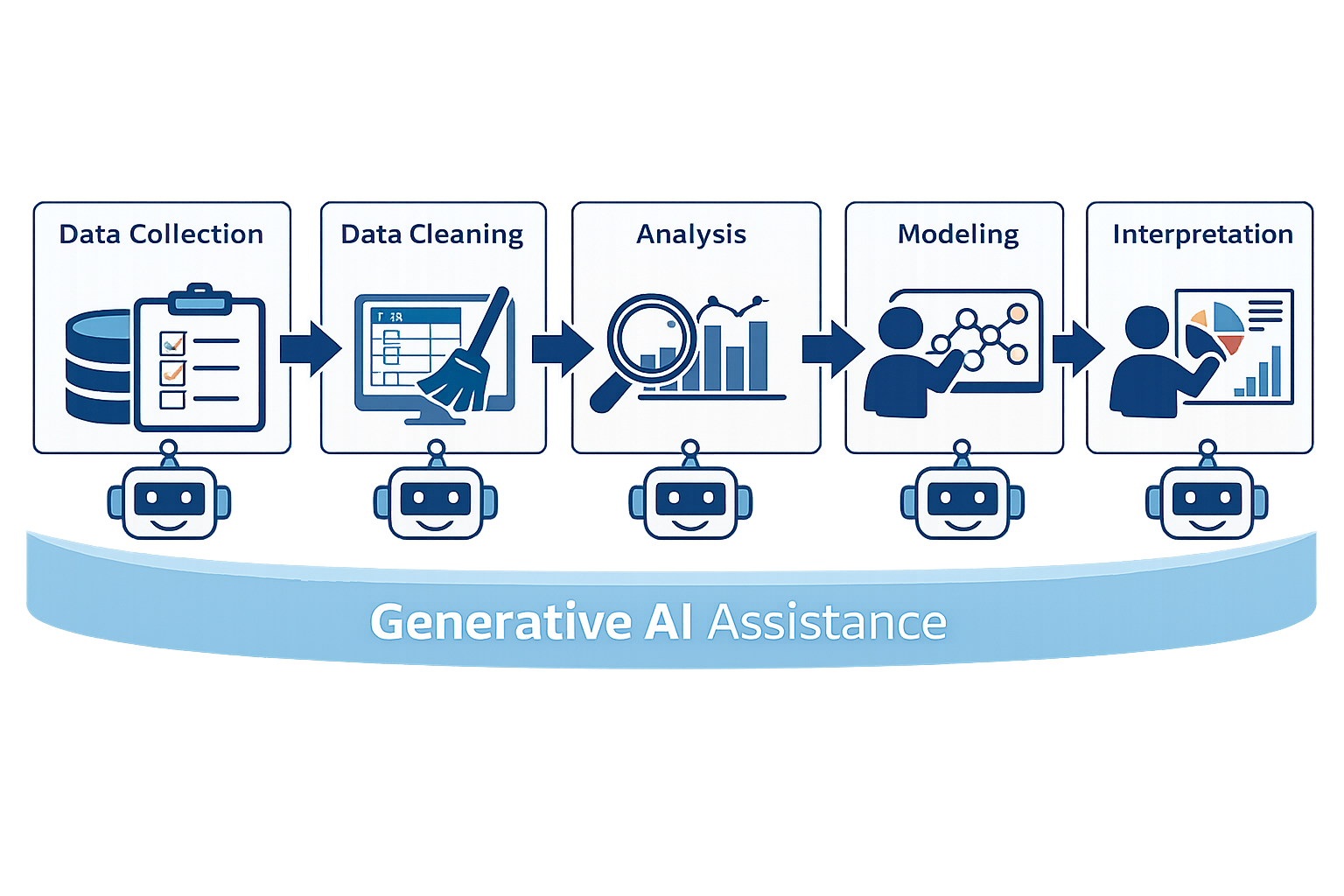
This gap between plausibility and correctness becomes especially visible when we look at the data science workflow end to end. At each stage, generative AI can help. However, it also quietly exposes whether the user understands what they are doing.
Data Collection and Cleaning
Generative AI can suggest common data cleaning steps almost instantly: handling missing values, encoding categorical variables, removing outliers. These suggestions often look reasonable. Yet, reasonable
is not the same as appropriate
. Removing outliers without understanding their origin can erase meaningful signal. Imputing missing values without examining why they are missing can introduce bias. An expert knows that cleaning is not a checklist; it is a set of decisions grounded in context and intent.
Exploratory Analysis
AI-generated plots can be visually appealing and quick to produce. But charts without context can mislead faster than having no charts at all. A correlation plot might look compelling, yet hide confounding variables. A trend line might imply stability where none exists. Experts use exploratory analysis to ask better questions, not to prematurely answer them. Without that mindset, visualization becomes decoration rather than insight.
Modeling and Evaluation
This is where problems often compound. Generative AI is very good at suggesting standard models and default evaluation metrics. Accuracy, precision, recall, and F1 scores. Howbeit,these appear frequently because they are common; whether they are appropriate depends entirely on the problem. A seasoned data scientist recognizes when a baseline is missing, when class imbalance distorts metrics, or when cross-validation has been applied incorrectly. A beginner, on the other hand, may see a high score and stop thinking.
Interpretation and Communication
Perhaps the most dangerous stage is interpretation. Generative AI can produce confident narratives that sound persuasive even when the underlying evidence is weak. It can explain patterns that do not generalize, or imply causality where only correlation exists. Without expertise, these narratives are easy to accept and even easier to present to others.
As illustrated in the Figure 1, generative AI can support every stage of the data science process. Nevertheless, it acts as a stress test of the user’s understanding at each step.
Expertise as the Bottleneck (Not Computation)

For a long time, computation was the bottleneck in data science. Models were expensive to run. Data pipelines were slow. Today, that bottleneck has largely disappeared. What remains scarce is not compute, but judgment.
Expertise shows up in subtle but crucial ways: asking the right questions, framing precise prompts, and knowing when an answer feels suspicious. It shows up in understanding statistical assumptions, ethical constraints, and domain-specific nuances that no generic model can infer reliably. It shows up in debugging reasoning, not just code.
Generative AI can generate many answers quickly, but it cannot tell you which answer matters. It cannot tell you which path is defensible, which result is fragile, or which conclusion would collapse under scrutiny. Those are human responsibilities.
In this sense, expertise has become the true bottleneck. The faster the tool, the more visible that bottleneck becomes.
When Generative AI Makes You Worse at Data Science
While generative AI can accelerate good practice, it can also actively make people worse at data science, especially beginners.

One reason is hallucination: the generation of confident but incorrect information (Ji et al. 2023). These errors are often subtle. A model may cite a non-existent method, apply a technique in the wrong context, or misstate a statistical principle. Experts tend to notice these issues because they already have mental models to compare against. Beginners often do not.
Another risk is overconfidence amplification. When an AI produces polished output, it can give users unwarranted confidence in their work. This leads to what might be called cargo-cult data science
: practices are followed because they look right, not because they are understood. Code runs, so it must be correct. A metric improves, so the model must be better.

Evidence (Figure 2) from practice supports this concern. In a recent industry survey of software developers, 96% reported that they do not fully trust AI-generated code to be functionally correct, yet only about 48% said they always check the code before using it, and 61% agreed that AI-generated code often appears correct even when it contains errors.
The consequences are not just academic. In real-world settings, these failures can lead to flawed decisions, biased systems, and ethical breaches. Over-reliance on generative AI does not merely reduce learning; it can undermine professional responsibility.
How Students Should Actually Use Generative AI
For students in data science, the question is not whether to use generative AI, but how to use it well.
Used properly, generative AI can be a powerful learning tool. It can help explain why certain methods are used, not just how to implement them. It can generate multiple alternative approaches, which students can then critique and compare. It can surface gaps in understanding by producing answers that prompt skepticism rather than acceptance.
What it should not be used for is replacing statistical reasoning or validating conclusions. AI should not be the authority that declares an analysis correct
. That role belongs to careful thinking, domain knowledge, and evidence.
Developing AI literacy on top of strong data science fundamentals is key. This means learning how to interrogate AI outputs, how to challenge them, and how to integrate them into a workflow without surrendering responsibility.

Conclusion: AI as a Mirror
Generative AI does not level the playing field in data science. Instead, it acts like a mirror. It reflects the quality of the thinking behind the prompt. It accelerates good data science and bad data science alike.
For those who can evaluate, critique, and contextualize its outputs, generative AI is a powerful assistant (Amershi et al. 2019). For those who cannot, it becomes a source of hidden risk. The tool itself is not the problem. The absence of expertise is.
The final takeaway is simple yet uncomfortable: if generative AI makes your work better, it is because you were already good. And if it makes your work worse, it is not because the tool failed; it is because it revealed what was missing.